The following is a list of the issues and solutions for the problems I encountered while installing 10gR2 RAC , OEL5 on VMware. Some of the items below are things I tried but didn't resolve an issue but I thought might be interesting.
1. If you are using vmware on a slow computer, especially when 2 nodes are running, you may experience locking issues. If so, it could be timeouts for the shared disk. In your vmware config files add the following:
reslck.timeout="1200"
On the bottom right hand side of your vmware window you will see disk icons that will flash green when they are in use. If vmware hangs and any of the shared disks are green then this is probably the issue.
2. Eth0 has to be bridged or you will see the following running vipca or in your vip log:
Interface eth0 checked failed (host=raclinux1)
Invalid parameters, or failed to bring up VIP (host=raclinux1)
3. If during the install you didn’t disable the firewall, root.sh will be unable to start on the second node, raclinux2. If so, disable iptables by executing:
/sbin/service iptables stop
To disable this feature from starting after a reboot, execute the following as root:
/usr/sbin/system-config-services
Scroll down until you see iptables, if it is checked, remove the check then click on the save button. You can also stop the services from this program as well by highlighting iptables and clicking the stop button.
Subject: Root.sh Unable To Start CRS On Second Node Doc ID: Note:369699.1
4. The following two workarounds are already addressed in the installation guide but here they are for reference.
Subject: VIPCA FAILS COMPLAINING THAT INTERFACE IS NOT PUBLIC Doc ID: Note:316583.1
Subject: 10gR2 RAC Install issues on Oracle EL5 or RHEL5 or SLES10 (VIPCA Failures) Doc ID: Note:414163.1
5. Subject:
CRS-0215: Could not start resource 'ora..vip' Doc ID:
Note:356535.1 During a VIP status check, your public interfaces gateway is pinged. If you don't have a gateway specified, this check will fail. If that action fails it assumes there is a problem with the Ethernet adapter interface. To resolve this, change the parameter FAIL_WHEN_DEFAULTGW_NOT_FOUND in the $ORA_CRS_HOME/bin/racgvip and set it to 0
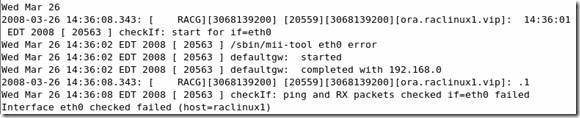
This doesn’t mean the VIP will failover, there are some additional checks. Also, the parameter FAIL_WHEN_DEFAULTGW_NOT_FOUND only applies if you don't have a gateway defined in your network setup. If you entered a gateway ip address as per my guide, even tho it may not be pingable, this will have no effect.
6. While troubleshooting VIP failovers I found the following note which details how to increase the timeouts for the VIP service. This didn’t solve any of the issues I encountered but I thought it may be interesting to note:
Subject: ASM Instance Shuts Down Cleanly On Its Own Doc ID: Note:277274.1
7. If you are using vmware on a slow computer you may experience a problem where the VIP’s failover frequently. If that happens you may want to set the following:
Increasing the value of the parameter CHECK_TIMES to 10 may help in this case.
In $ORA_CRS_HOME/bin/racgvip set the following line:
# number of time to check to determine if the interface is down
CHECK_TIMES=2
-- to --
# number of time to check to determine if the interface is down
CHECK_TIMES=10
NOTE: This will only help when the problem is because of slow response from the gateway. Please do NOT use this workaround in other situations. This will have sideaffect of increasing the time to detect a unresponsive public interface.
Subject: VIP Going Offline Intermittantly - Slow Response from Default Gateway Doc ID: Note:399213.1
8.
CRS services in an unknown state after reboot. Watching the crs logs I noticed the services weren’t waiting for the appropriate timeout value before erroring. This is a bug with 10.2.0.1 CRS:
Patch 4698419
[10201-050630.0024A_LINUX64]STARTING CRS RESOURCES FAILS WITHOUT WAITING TIMEOUT


























![clip_image002[1]](http://lh6.ggpht.com/david.best/SB4LgYDKWmI/AAAAAAAAAy0/TitvoVa4FqM/s1600-h/clip_image0021%5B1%5D.jpg)
![clip_image004[1]](http://lh6.ggpht.com/david.best/SBzXa4DKWOI/AAAAAAAAAzA/6hv7mdza8PU/s1600-h/clip_image0041%5B4%5D.jpg)
![clip_image006[1]](http://lh3.ggpht.com/david.best/SBzXcIDKWQI/AAAAAAAAAzI/PH5AMrCXf2A/s1600-h/clip_image0061%5B1%5D.jpg)
![clip_image008[1]](http://lh4.ggpht.com/david.best/SBzXdYDKWSI/AAAAAAAAAzQ/wI9a2hhT3C4/s1600-h/clip_image0081%5B1%5D.jpg)
![clip_image010[1]](http://lh5.ggpht.com/david.best/SBzXeoDKWUI/AAAAAAAAAzY/IBEZjnAvoH0/s1600-h/clip_image0101%5B1%5D.jpg)
![clip_image012[1]](http://lh6.ggpht.com/david.best/SBzXf4DKWWI/AAAAAAAAAzg/fT895UIUZRU/s1600-h/clip_image0121%5B1%5D.jpg)
![clip_image014[1]](http://lh4.ggpht.com/david.best/SBzXhYDKWYI/AAAAAAAAAzo/n1gpohtaMkE/s1600-h/clip_image0141%5B1%5D.jpg)
![clip_image016[1]](http://lh3.ggpht.com/david.best/SBzXjIDKWaI/AAAAAAAAAzw/k4oOl33WJ5I/s1600-h/clip_image0161%5B1%5D.jpg)
![clip_image018[1]](http://lh4.ggpht.com/david.best/SBzXkYDKWcI/AAAAAAAAA0g/Qy6J3IhAxZM/s1600-h/clip_image0181%5B6%5D.jpg)
![clip_image020[1]](http://lh3.ggpht.com/david.best/SBzXlIDKWeI/AAAAAAAAA0o/EpP9-L54c5Q/s1600-h/clip_image0201%5B2%5D.jpg)
![clip_image022[1]](http://lh6.ggpht.com/david.best/SBzXl4DKWgI/AAAAAAAAA0w/4QHZMD-vNRQ/s1600-h/clip_image0221%5B2%5D.jpg)
![clip_image024[1]](http://lh5.ggpht.com/david.best/SBzXmoDKWiI/AAAAAAAAA04/vegVfy9XStU/s1600-h/clip_image0241%5B2%5D.jpg)
![clip_image026[1]](http://lh6.ggpht.com/david.best/SBzXn4DKWkI/AAAAAAAAA1A/AnhOoMl-B68/s1600-h/clip_image0261%5B2%5D.jpg)































































{kind=link}